
Unmasking AI: Decoding Decisions with SHAP
When most people hear ‘AI bias’, they think of algorithmic bias, where a Machine Learning model produces systematically unfair outcomes, often to specific groups of people. However, it is less common to discuss automation bias, where a human being is overly trusting in the decision of a machine, even to the point of ignoring contradictory evidence on the machine’s limitations. For example, you might continue to follow a GPS as it leads you into a muddy field instead of onto a nearby road, believing ‘the GPS knows what it’s doing (better than I do!)’.
Automation bias can be hugely problematic, and cause issues far worse than a car stuck in the mud. In 1983, Stanislav Petrov, who oversaw the USSR’s warning system to detect US missiles in the Cold War, was notified of incoming nuclear warheads. Had Petrov succumbed to automation bias, blindly trusted the machine, and informed his superiors, the policy of mutually assured destruction would have seen the beginning of nuclear war. Instead, Petrov was suspicious that the system had only detected one missile (one might expect several hundred to commence nuclear war), and judged the machine to be mistaken; he was indeed correct.
One way to counteract automation bias is to better understand the machine’s decision making process, allowing us to make a more informed decision as to whether to believe it. In order to do this, we can use techniques from eXplainable Artificial Intelligence (XAI).
What is XAI?
XAI is a collection of techniques and attitudes to understand the decision process of a Machine Learning model. Where it feels impossible to know why ChatGPT chose to reply with the words it did, or how your iPhone recognised a blurry image as having your face in it, XAI allows us to gain insight to find these answers.
Each XAI technique will use a different process to provide an explanation of a machine learning model, but ultimately all use at least one of two core ideas. ‘Self-explaining’ techniques limit the complexity of a model as it trains, so that when finished, the model is simple enough to directly interpret its inner workings. On the other hand, ‘post-hoc’ methods perform analysis of the internal workings of any pre-existing model, regardless of complexity, and produce statistics to explain the model to a human.
How much can XAI explain?
Different XAI techniques can give varying levels of insight, with three main options. Local techniques explain how a model makes a specific prediction or decision; the technique is provided with a given input to the model and explains the output that the model returns. With a local model, we can look to answer the question “Why did the GPS send me through a field on my drive today?”
However, cohort techniques can give a mass explanation of a collection of similar data points all at once, helping provide a general overview of how a model might give a specific outcome. For instance, we could use a cohort method to know “Why does the GPS send me through fields?”
Lastly, global techniques explain a model in its entirety, with little to no reference to the input data points, but instead providing a general understanding of how the model makes decisions on any input. With a global method, we can know “How does the GPS use the route length, quality, etc. to choose a route?”
Each of these techniques are useful in its own right, because the question each answers is different. A global method is often unhelpful in explaining an individual prediction if that prediction is not very representative of the whole dataset. Conversely, it would be false to generalise the model from a local explanation, which only gives a scope of view.
What XAI techniques exist?
As a growing field of AI research, a wide variety of techniques exist. Some are suited to specific models, such as working best on neural networks, or decision trees. Other techniques are known as ‘model agnostic’ and can be applied to all possible models, and it is on one of these that we will focus on, known as SHAP.
SHAP (SHapely Additive exPlanations) is an incredibly popular XAI technique, which is:
Model agnostic, so can be used on all types of models
Capable of local, cohort, and global explanations, so can provide both sweeping overviews and specific details
A post-hoc method, so can be applied to models that already exist without needing to retrain them.
SHAP was invented in 2017 by Scott Lundberg and Su-In Lee. Lundberg and Lee built upon ideas of previous XAI methods, and combined those into a single flexible and consistent schema. Since its inception, it’s been well established as a gold standard in the field of XAI. As well as the flexibility noted above, it also has a strong mathematical and statistical grounding, keeping it rigorous, and a python library already exists to implement it, making it easy to use.
How does SHAP work?
Given an input datapoint, SHAP aims to allocate each feature a score to detail in what direction the feature value contributed to the output, and on what scale. Take the example of the GPS taking you through a muddy field rather than a nearby road, and let’s focus on the feature detailing the length of a route. SHAP might give the field’s length a score of +1.7, with the + indicating that the field route being short helped the model to suggest it, and the 1.7 (being large) showing this knowledge heavily contributed to the final decision. Maybe on a different, long route, SHAP gave the distance a score of -1.8, i.e. the route length significantly helped the model to not recommend it.
If we run this technique over a variety of data points, we can begin to build up a general picture of how each feature of the model is used; perhaps on lots of navigation requests, a route being short heavily contributed to that route being chosen, and we conclude that the model favours short routes.
What makes SHAP powerful are these numerical scores; by averaging the scale SHAP assigns to a feature across multiple data points, we get an overall score for how that feature is used. For instance, if we get scores of +1.7, +1.9, and -1.8 for 3 different routes, we average the numbers (ignoring the signs) to score the importance of route distance as 1.8. We can then compare this to the equivalent statistic for road quality, say 0.4, to see that the model is more attentive to route distance than road quality, justifying why it picked to send you through the mud!
What’s going on mathematically?
The core idea of SHAP is averages; SHAP asks “How did a route distance of 1km instead of the average distance of 0.5km change the average output of 50-50 field vs road?” and uses famous Game Theory statistics called Shapely Values [1] to make these calculations.
By combining the SHAP contributions of each feature of a given datapoint, we can see how the features came together to give the final model output, rather than the average output (i.e. the output averaging across all of the possible inputs). The graph below gives a good example of this.
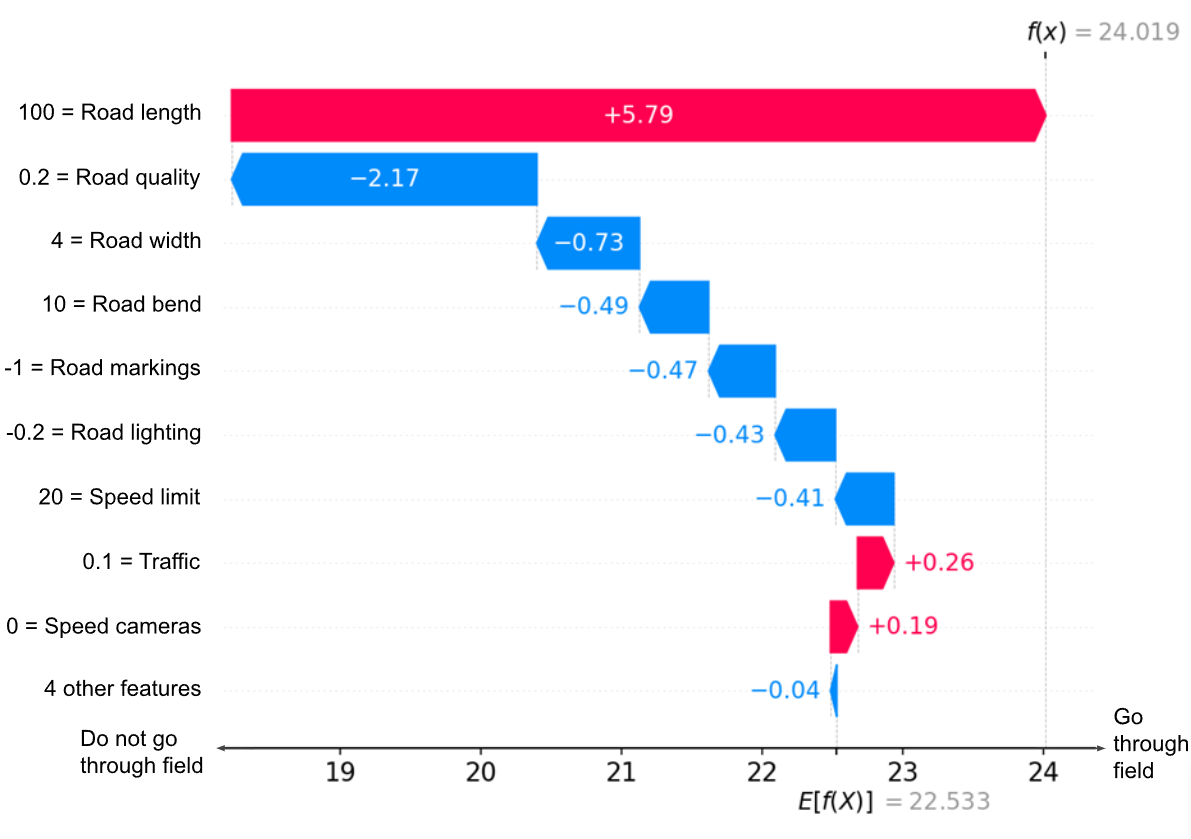
Figure 1. Example of a SHAP ‘Waterfall’ plot, summarising how each feature’s SHAP value moves the model’s output away from the model output mean. Figure adapted from SHAP documentation [2].
Here, we can see that the majority of features for this datapoint were leading the model to predict more against going through the field than the average (E[f(X)]) prediction, but the road being of length 100 was extremely important in producing a larger number, f(X) = 24.019, and thus predicting this route.
Are there any drawbacks to SHAP?
As with most XAI methods, SHAP results are prone to confirmation bias, where humans read the results they were expecting to see, and ignore things they don’t agree with or weren’t expecting. For example, suppose one of our features is whether or not the M6 appears in the route. Counterintuitively, having the M6 in the route might give a negative SHAP value, even though motorways should make routes faster. If we don’t know specifics about UK roads, we might focus on the SHAP results about route length and road quality, assuming this M6 issue is a mistake, and in doing so, fall to confirmation bias. We must work hard to treat all explanations as equally correct (up to the scale of importance SHAP gave us), and so should look to resolve this conundrum (perhaps the GPS has been set to avoid toll booths, of which one can be found on the M6!)
In fact, the above paragraph demonstrates another fallacy that can arise when interpreting SHAP, which is overinterpreting the results. At no point does SHAP mention anything to do with toll booths, so we cannot draw the conclusion that that is why the model is avoiding the M6. SHAP only tells us the model avoids the M6, not why! This is an example of ‘imposing a narrative’ - creating a believable story which fits the statistics, but is not directly given by them.
Lastly, the exact calculation of SHAP values is exponential in the feature size of the model. As a result, approximation methods have to be implemented, most commonly KernelSHAP. These methods give a significant speedup, but come at the cost of reducing the mathematical precision that made SHAP so appealing.
How can we use XAI techniques to eliminate unconscious bias?
We have discussed XAI through the lens of automation bias, but in fact there are wider use cases, including MeVitae’s. Because model agnostic techniques like SHAP can explain any possible model, we can gain insights to spot hidden identifying information in CVs by explaining how an AI classifier might detect a CV to be of a certain gender, race, or age.
When we see which features of a CV can be used by a classifier to make predictions, we can identify exactly what in a CV may reveal an author’s protected characteristics. For instance, if SHAP assigns a positive score to apostrophes (when a positive classification means lower age), we can conclude that the use of apostrophes is more common among younger authors. From this we might conclude that apostrophe use might betray an author’s age. (Perhaps younger writers use more contractions in their CVs!) We can use this to inform on a more neutral writing style, or improve blind recruiting tools by considering the transformation of contractions into full words.
Overall, XAI techniques provide us with the power to better understand a model’s decision making process, and therefore allow us to place trust in Machine Learning without the risk of automation bias. The applications of this stretch far and wide, and with each year come new papers of novel XAI techniques in more exciting use cases. If we move into a world where complicated models are given less oversight, XAI will be crucial in knowing our models behave as they should. By returning the knowledge from the model back to humans, XAI has the potential to revolutionise the field of Machine Learning.
Author: Lewis Wood (Algorithm developer)